Power Platform Connector Building Blocks

In part two of this series, we walked through each step in the connector creation wizard, identified the creation activities that can be performed within the user interface, and previewed the underlying definition file produced from these activities. We also looked briefly at the options for securing a custom connector, outlined the process for configuring requests and responses, and showed how to validate a completed connector directly within the wizard.
This article sets the user interface aside, delving into various sections of the connector definition file and the elements contained within each one. It begins with a more thorough discussion of connector security, focusing on OAuth, the most complex of the four available authentication methods to configure. It then moves on to the definition of request and response operations within action paths, covering verbs, parameters, properties, schemas, media types, and examples, including how to use tags to group and organize connector operations. Using this article and the previous articles in the series, creators should be able to build a custom connector from a blank template. They should also be able to understand what is happening behind the scenes to better analyze, troubleshoot, and optimize their connectors.
For reference, the series outline is as follows:
- Introduction and Overview
- Connector Fundamentals
- Basic Building Blocks: Security, Actions, Requests, and Responses (this article)
- Advanced Capabilities: Triggers, References, and Policies
- Finishing Touches: Customization and Extensibility
- Staying In Control: Versioning and Change Management
- The Big Picture: Performance, Hosting, and Scalability
- Making It Official: Publishing, Certification, and Deployment
- Going All In: Commercialization and Monetization
- Lessons Learned: Tips, Tricks, and Advanced Techniques
Security
The security section within a definition is comprised of a securityDefinition node at the root of the definition structure and individual security nodes that can exist either at the root, providing a global implementation of one or more security definitions, within specific actions for localized security directives, or both. The securityDefinition node sets forth what security mechanisms are supported and defines their properties. A security node states which of the allowed mechanisms should be used when a connector action is invoked.
The following definition snippet describes an API Key security mechanism that is then applied to the entire connector using a header parameter (no security nodes need to be included within the action paths as the global setting will apply to all):
"securityDefinitions": {
"API Key": {
"type": "apiKey",
"in": "header",
"name": "api_key"
}
},
"security": [
{
"API Key": []
}
],This next definition snippet takes a different approach, defining one security mechanism (API Key) that can be applied in two different places, either the request header or the query string. By default, the api_key parameter will always be sent in the header, but the /v1/feed action will also provide it in the query string of the GET operation.
"securityDefinitions": {
"headerKey": {
"type": "apiKey",
"name": "api_key",
"in": "header"
},
"queryKey": {
"type": "apiKey",
"name": "api_key",
"in": "query"
}
},
"security": [
{
"headerKey": []
}
],
"paths": {
"/v1/feed": {
"get": {
"description": "Retrieve a list of Asteroids based on their closest approach date to Earth",
"summary": "Approaching asteroids",
"operationId": "feed",
"security": [
{
"queryKey": []
}
],
}
}
}It is also permissible to mix security mechanisms within a single definition. The following snippet defines a global OAuth mechanism while the /v1/feed action instead uses the API Key mechanism:
"securityDefinitions": {
"oauth2-auth": {
"type": "oauth2",
"flow": "accessCode",
"authorizationUrl": "https://api.example.com/api/authorize",
"tokenUrl": "https://api.example.com/api/token",
"scopes": {
"user.read": "user.read"
}
},
"queryKey": {
"type": "apiKey",
"name": "api_key",
"in": "query"
}
},
"security": [
{
"oauth2-auth": [
"user.read"
]
}
],
"paths": {
"/v1/feed": {
"get": {
"description": "Retrieve a list of Asteroids based on their closest approach date to Earth",
"summary": "Approaching asteroids",
"operationId": "feed",
"security": [
{
"queryKey": []
}
],
}
}
}Be aware that using such a configuration requires creating multiple connections within Power Platform for the connector—one for each defined security mechanism. This can become difficult to manage and can lead to user confusion. It also makes the definition harder to update and maintain, especially when there are many actions, each either specifying a particular mechanism or inheriting from the default. Exercise caution so as not to make the security aspects more difficult than necessary.
OAuth
OAuth, which stands for Open Authorization, is an open-standard authorization framework that describes how unrelated servers and services can safely allow authenticated access to their assets without sharing the logon credentials. This is known more broadly as third-party, delegated authorization. Prior to the implementation of OAuth, granting third-party access from one service to data stored in another service meant supplying a username and password. From a security perspective, this is far from ideal, as it effectively gives full access to the data as if a real human being were logging into the application. Also, it is difficult to restrict the level or duration of access without changing roles and passwords.
OAuth was created to solve these problems. With OAuth, a third-party application can be provided with permissions to access a user’s data without sharing any passwords. Instead, OAuth provides a token to the third-party application. This token grants access to specific resources for a limited duration and restricts the operations that can be performed. For example, it might allow a photo printing service to access a specific photo album in a social media service for a day. After that period, the token expires, and access is automatically revoked. Furthermore, it may only be permitted to read images within the album, while not being able to make any modifications.
Today, OAuth is widely used as a way for internet users to grant websites or applications access to their information on other websites without the use of passwords. In fact, OAuth is very explicitly designed to avoid authentication altogether, which is why it is referred to as authorization. It is assumed that the user has already logged into one or more systems using verified credentials before they are permitted to configure an OAuth flow. There are different paths that the token grant process can follow. Essentially, however, a successful exchange consists of a client requesting authorization from a resource owner, an access token being provided to the client after the authorization request has been verified, and a protected resource accepting the token as proof of authorization.
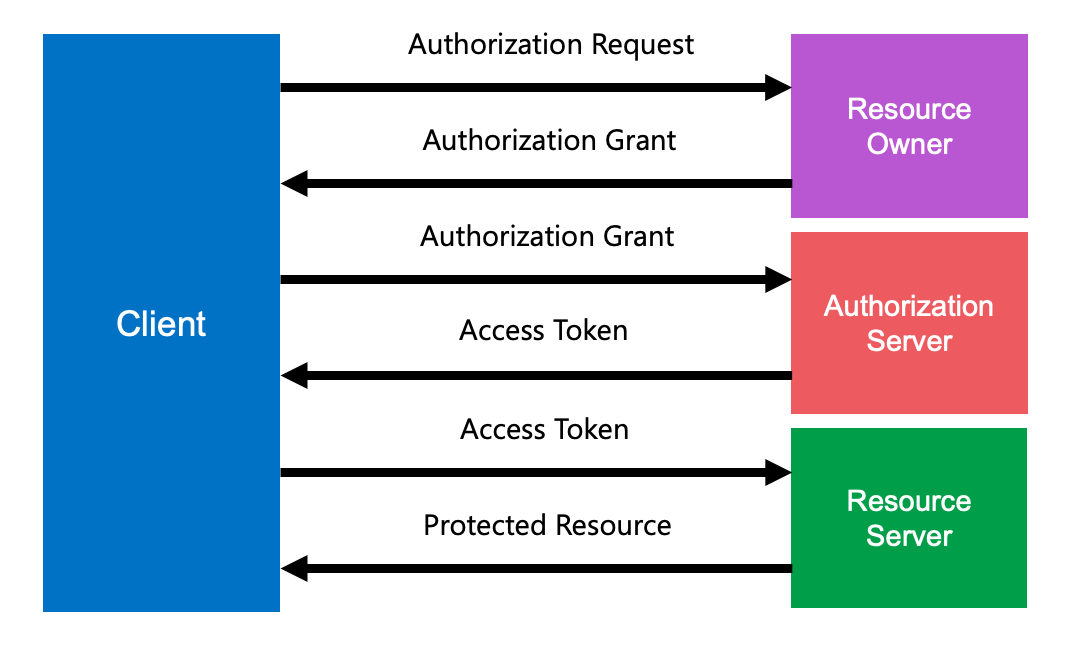
There are several different flows that can occur based on the specified grant type. Software and service vendors have also implemented their own variants of these flows, creating a somewhat confusing patchwork of flow mechanisms. For the sake of simplicity, the various permutations can be grouped under the basic categories of Authorization, Client Credential, and Implicit. (There is a fourth category named password that is enumerated in the OpenAPI specification. Since the whole point of OAuth is to avoid transmitting usernames and passwords, however, it is best avoided unless an API resource owner specifically requires it.) Each flow category is designed to serve a specific set of use cases. Although they share the same underlying concepts, how they are configured and executed varies significantly.
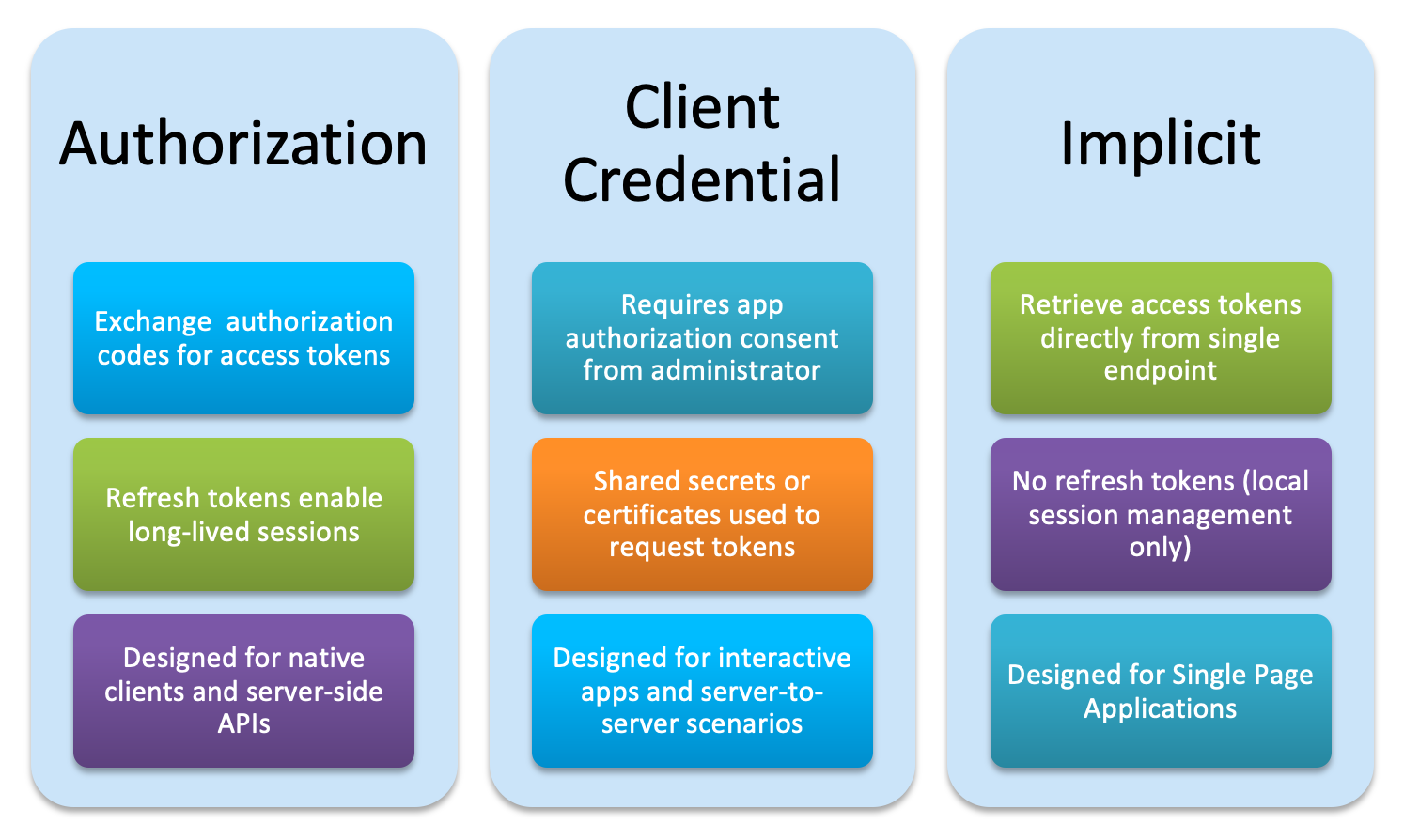
The preceding diagram pertains specifically to apps implementing OAuth within the Microsoft 365 and Azure ecosystems; however, the principles are nearly identical across vendor implementations. Both Authorization and Implicit flows assume some level of user interaction, but they differ on how often that interaction can occur and what happens between such interactions. An Authorization flow involves a trusted client or caller that can securely store data, like refresh tokens, to reduce the number of times a user has to authenticate against the host system. Implicit flows are more suited to mobile and browser-based apps in which token storage cannot be assumed to be secure. The Client Credential flow supports more complex scenarios that involve long running operations, automated processes, and situations where user interaction is sparse or non-existent.
The connector creation wizard offers a variety of pre-configured OAuth identity providers, along with a Generic OAuth 2 provider, all of which implement the Client Credential flow mechanism. The wizard prompts for these inputs when selecting the generic provider, but it obfuscates the various URLs for known providers. It also marks the response URL as a required field, even though it is completely optional. Simply enter a placeholder value in that field if the API provider does not provide one. Scopes are also optional depending upon what the provider supports. If none are provided, this field can be left blank.
The Redirect URL field is disabled during initial configuration. This must be a publicly accessible URL that the API provider or target system can reach via a standard HTTPS request on port 443. As such, it is beyond the creator’s control to specify this value, so Power Platform will insert it into the connector configuration and display it after the connector is saved. This is not a value that is included in the definition but rather one that the creator will need when configuring OAuth in the target system to generate Client ID and Secret values.
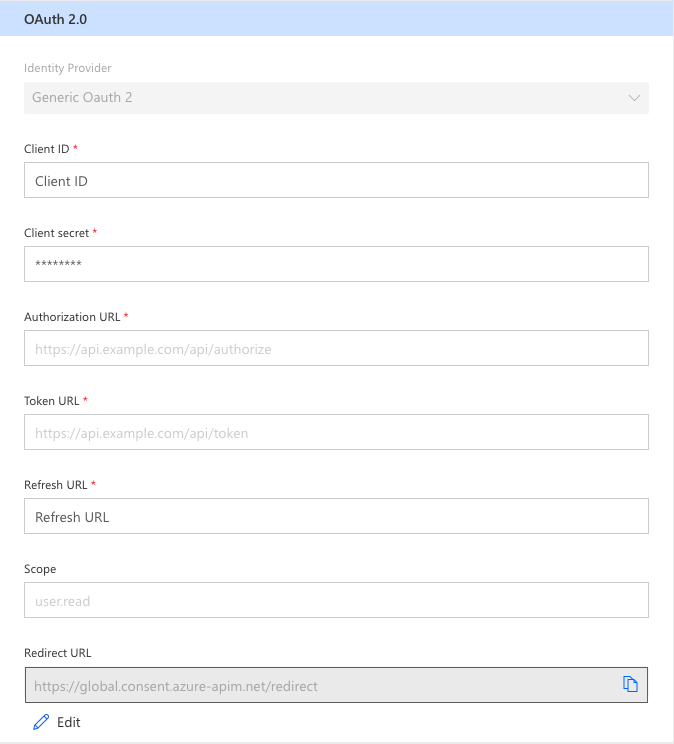
Based on the information in the form, the wizard produces a security definition like the following:
"securityDefinitions": {
"oauth2-auth": {
"type": "oauth2",
"flow": "accessCode",
"authorizationUrl": "https://api.example.com/api/authorize",
"tokenUrl": "https://api.example.com/api/token",
"scopes": {
"user.read": "user.read"
}
}
},
"security": [
{
"oauth2-auth": [
"user.read"
]
}
],Note that the flow property in the securityDefinitions section that the wizard generates has its value set to accessCode. This does not comply with the actual Swagger specification, which requires that the client credential flow be specified using a value of application. The accessCode value is reserved for Authorization Code flows. The naming convention confusion has been dispelled in OpenAPI Version 3, wherein accessCode has been renamed to authorizationCode and application to clientCredentials. Despite this discrepancy between the wizard output and the underlying specification, Power Platform does execute the correct flow. It just appears to be an improper configuration, since the settings may not match what the API provider has specified in their documentation.
The point of all OAuth flows is for the client to receive an access token that allows it to gain access to the target system. Scopes, if defined, restrict operations that the client can perform once it has been granted access. The actual payload within an access token response varies from system to system. Typically, it contains the following elements:
- A unique alphanumeric key or hash to serve as the token itself
- A property to indicate the underlying type
- An expiration value that dictates the usable lifetime of the token
- A refresh token value for systems that provide token refresh capabilities
- A set of scopes
This is an example of a very simple access token response:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-store
{
"access_token":"MTQ0NjJkZmQ5OTM2NDE1ZTZjNGZmZjI3",
"token_type":"Bearer",
"expires_in":3600,
"refresh_token":"IwOGYzYTlmM2YxOTQ5MGE3YmNmMDFkNTVk",
"scope":"create"
}Using an access token in the manner dictated (for example, as the value for an Authorization header parameter preceded by the token_type value from the response) as part of an action allows the target system to evaluate credentials and permissions for each request. If the OAuth parameters are set at the top level of the definition, all actions will use them; however, it may be necessary to specify different security settings for specific actions. If, for example, a GET action requires a user.read scope but a POST action requires user.write, then the security object can be applied at the action level and will override the global setting. This is why the scopes property of each securityDefinition object allows for multiple entries and the corresponding references within the security object are followed by an array of scope names. In this manner, multiple scope combinations within a single definition can be used to dictate a very specific permission profile for each action.
The API provider dictates the scope values. There is no standard naming convention, and they can be any combination of alphanumeric characters. While most providers attempt to follow some sort of logical naming sequence, like the dotted notation Microsoft uses, there is no guarantee that there will any level of consistency to these elements. Carefully review the provider documentation to determine which scopes are required for each action and how they should be referenced. (See the Microsoft Graph permission reference at https://learn.microsoft.com/en-us/graph/permissions-reference.)
Actions
Actions, also known as paths, represent the user-facing components within a specification. If we think of a connector definition as a tall building, the information, security, host, path, tags, and other top-level elements represent the foundation and structure, while the actions represent each floor. Some floors may serve very similar purposes, but have different layouts. Meanwhile, other floors are designed for a particular purpose and bear very little similarity to the floors above or below them. Some may have different access methods (like stairs or elevators), be secured by passkeys and locks, or be completely open to the public.
Each action behaves as a self-contained unit that leverages the shared structure of the connector definition base to perform a singular operation. There are no composite or linked actions within a definition—each is executed individually, and they cannot pass information between them. Like the layout of each floor in our metaphorical building, settings and configuration elements are also unique to each action; however, there are several such elements that each action has in common. The general structure of an action should look similar to the following:
- path
- verb
- properties
- tags
- parameters
- properties
- schema
- consumes
- produces
- responses
- response code or default
- properties
- schema
- response code or default
- examples
- verb
Path
The path element is the root node of an action. It defines the relative URL that the request will be sent to and must be in a URL format that typically includes a leading forward slash ("/"). At runtime, the path is combined with the scheme, host, and basePath properties of the definition to produce a fully qualified URL in the following manner:
{scheme}://{host}{basePath}{path}{parameters}A path may contain as many forward slashes as necessary, but it cannot contain any query parameters. A value of "/items" is acceptable but "/items?id" is not allowed. Whenever query string arguments are needed, they should be declared in the parameters section with an in value of query. These will automatically be appended to the full URL at runtime.
A path with a query parameter would be defined in the following manner:
"paths": {
"/v1/feed": {
"get": {
…
"parameters": [
{
"name": "start_date",
"in": "query",
"required": false,
"type": "string"
},
…
]
}
}
}This would produce a full URL like the following (with user input providing the actual start date value):
https://api.nasa.gov/neo/rest/v1/feed?start_date=2023-01-01Paths may include variables, indicated by the use of curly braces ("{}") surrounding a value in the URL. These are known as path templates in the Swagger specification. Each variable included in the path must have a matching parameter of the same name in the parameters section of the action object with the in property set to path. For example, if the version identifier in the path were changed to a dynamic value determined by the user, the definition might look like the following:
"paths": {
"/{version}/feed": {
"get": {
…
"parameters": [
{
"name": "version",
"in": "path",
"required": true,
"type": "string"
},
…
]
}
}
}Verb
The verb property determines what kind of HTTP request is sent to the target URL. Swagger 2.0 supports the following verbs: get, post, put, patch, delete, head, and options. Each verb defines a different type of operation to be performed. For example, when a get request is issued, it is typically used for read-only operations. (That is not a rule, simply a common implementation—although rare, and in conflict with the REST standards, some systems may perform write operations based on a get request.) A delete request is intended to remove something, usually a record or entry of some sort, from the target system. The list identifies the common implementations of HTTP verbs in a RESTful context:
- get: Read data from the resource without modifying it (may or may not include parameters in the path or query string to identify specific items to be retrieved).
- post: Create or update an item in the resource (may or may not include parameters, optionally in the path, query string, or body, to identify a specific item), often used as catch all for any type of operation.
- put: Update an entire item in the resource (should include parameters, optionally in the path, query string, or body, to identify a specific item); typically replaces an entire item but may also be a partial update.
- patch: Partially update an item in the resource (should include parameters, optionally in the path, query string, or body, to identify a specific item).
- delete: Remove an item in the resource (should include parameters, optionally in the path, query string, or body, to identify a specific item).
- head: Retrieve metadata headers from the resource without a message body in the response (may or may not include parameters in the path or query string to identify specific items to be retrieved), often used as a lightweight method for validating that a resource or resource item exists.
- options: A preflight request to check the validity of cross-origin (CORS) requests, typically returns a list of which methods are supported by the resource.
An action may include multiple verb configurations, each with its own set of properties and parameters, depending upon whether the target system supports them. Whenever a verb is combined with a data object being sent to the resource, the creator must specify which type of data object will be used by setting the in parameter to either body or formData. The former indicates that the payload of the request will be comprised of a text-based value or object (like JSON or XML). The latter is used when the resource expects something like a file or a compound object consisting of files and form field data.
Extending the previous examples, if the /v1/feed endpoint also supports a post operation that accepts the start_date and end_date values, then it could be structured like the following:
"paths": {
"/v1/feed": {
"get": {
"parameters": [
{
"name": "start_date",
"in": "query",
"required": false,
"type": "string"
},
]
},
"post": {
"parameters": [
{
"name": "startDate",
"in": "body",
"schema": {
"type": "object",
"required": [
"start_date"
],
"properties": {
"start_date": {
"type": "string",
"description": "Start date of query"
},
"end_date": {
"type": "string",
"description": "End date of query"
}
}
}
}
]
}
}Properties
Each action operation contains a set of defining properties within the verb object. Some are descriptive and provide general information about the operation, such as description and summary. Others specify the actual structure of the request and response. Not all properties are required, and some may be excluded from the definition entirely. The base fields listed in the Swagger specification are as follows:
- tags: A list of tags for API documentation control. Resources or any other qualifier can use tags for logical grouping of operations.
- description: A verbose explanation of the operation behavior. GFM syntax (GitHub Flavored Markdown) can be used for rich text representation.
- summary: A short summary of what the operation does. For maximum readability, this field SHOULD be less than 120 characters.
- externalDocs: A URL pointing to external documentation for this operation.
- operationId: Unique string used to identify the operation. The id MUST be unique among all operations described in the API. Tools and libraries MAY use the operationId to uniquely identify an operation. Therefore, it is recommended to follow common programming naming conventions.
- consumes: A list of MIME types the operation can consume. This overrides the consumes definition at the Swagger Object. An empty value MAY be used to clear the global definition or to indicate that any MIME type is acceptable. Value MUST be as described under Mime Types.
- produces: A list of MIME types the operation can produce. This overrides the produces definition at the Swagger Object. An empty value MAY be used to clear the global definition or to indicate that there is no restriction on MIME type. Value MUST be as described under Mime Types.
- parameters: A list of parameters that are applicable for this operation. If a parameter is already defined at the Path Item, the new definition will override it, but can never remove it. The list MUST NOT include duplicated parameters. A unique parameter is defined by a combination of a name and location. The list can use the Reference Object to link to parameters that are defined at the Swagger Object's parameters. There can be one "body" parameter at most.
- responses - Required: The list of possible responses as they are returned from executing this operation.
- schemes: The transfer protocol for the operation. Values MUST be from the list: "http", "https", "ws", "wss". The value overrides the Swagger Object schemes definition.
- deprecated: Declares this operation to be deprecated. Usage of the declared operation should be refrained. Default value is false.
- security: A declaration of which security schemes are applied for this operation. The list of values describes alternative security schemes that can be used. This definition overrides any declared top-level security. To remove a top-level security declaration, an empty array can be used.
Systems that support the OpenAPI specification format may also include their own custom properties, referred to as Vendor Extensions. Microsoft uses several custom properties, including x-ms-summary and x-ms-visibility, to provide additional information that Power Platform needs to render or execute an action. The value of a custom property may be null, a supported primitive (such as string, integer, dateTime, etc.), or an object. All custom properties must begin with the prefix "x-" and should make use of dashes to separate individual words. They are intended for use within a singular ecosystem, but some platforms do recognize other extensions. Nintex, for example, recognizes the Microsoft x-ms-summary property in their Automation Cloud service.
The following example demonstrates some basic properties for an operation:
"paths": {
"/v1/feed": {
"get": {
"description": "Retrieve a list of Asteroids based on their closest approach date to Earth",
"summary": "Approaching asteroids",
"operationId": "feed",
…
}
}
}Tags
As a definition increases in size, it is easy to lose track of what operations should be logically grouped together and challenging to display an orderly list of operations to the user. This can partially be achieved using naming conventions in the summary property by pre-pending a group name (such as Finance – Stock Quote); however, that does not resolve the problem of grouping related operations together in a graphical user interface. Tags solve this problem by first defining all supported tags at the root level of definition, and then assigning an action to one or more of those tags.
A tag can be any alphanumeric string desired by the definition creator. As they are only used for organizational purposes, they do not affect the connector operation in any way. Power Platform supports the tags but does not currently group actions by their assigned tags in the New action selection form or provide a mechanism for creating them in the wizard; however, it does display tag groupings properly in the Test interface.
To define a tag that can be assigned to actions, create a tags object at the root level of the definition that contains an array of objects, each with name and description properties:
"tags": [
{
"name": "NEO",
"description": "Near-earth objects."
}
]The specified tag may then be referenced within an action:
"/v1/feed": {
"get": {
"description": "Retrieve a list of Asteroids based on their closest approach date to Earth",
"summary": "Approaching asteroids",
"operationId": "feed",
"tags": [ "NEO" ],
…
}
}In a Swagger-compliant user interface such as https://editor.swagger.io, these tags may be rendered in such a manner as to produce logical groupings that are more easily navigated by end users.
Parameters
An operation can simply be an endpoint that returns data without requiring any type of conditions or filters to be specified, but most operations within a connector expect some sort of input values—a record identifier, date range for a filter, source text to modify, number of results, and so on. Parameters can be as simple as a few text fields, as complex as a nested JSON object, or even a file. These can all be combined into a single set of parameters that are displayed together on an input form, with some being optional and others required.
Parameter Properties
The parameter properties dictate how it will be displayed, what portion of the request it should be included in (header, query, body), and what the schema (structure) of the parameter should look like. Schema objects also have their own properties and, somewhat confusingly, a separate properties element within them. Parameter properties do not have a specific parent element other than the parameters node itself. Common parameter properties include:
- name – Required: If the parameter is located in the request path (as a query string argument), then the name must correspond to the associated path segment. Otherwise, it may be any alphanumeric value, but should not contain special characters that would not be allowable in a post/put/patch/delete operation.
- in – Required: The location of the parameter. Possible values are query, header, path, formData or body.
- description: A brief description of the parameter. This could contain examples of use. GFM syntax can be used for rich text representation.
- required: Determines whether this parameter is mandatory. If the parameter is in the path, this property is required, and its value MUST be true. Otherwise, the property MAY be included, and its default value is false.
- schema: An object that defines the structure of the request body.
If the value of the in property is anything other than body, then the following fields may also apply:
- type – Required: Limited to simple types that can be passed in a query string or form post, such as string, number, integer, boolean, array, or file. If the type is file, then the consumes value of the operation must be either multipart/form-data or application/x-www-form-urlencoded (or both) and the in parameter MUST have a value of formData.
- allowEmptyValue: Sets the ability to pass empty-valued parameters. This is valid only for either query or formData parameters and allows sending a parameter with a name only or an empty value. Default value is false.
- items – Required if type is array: Describes the type of items in the array (which can only contain primitive values, as discussed above).
- default: Declares the value of the parameter that the server will use if none is provided (such as the default selection from an array). Value must match the indicated type value.
There are also some potentially applicable fields like maximum, exclusiveMaximum, maxLength, pattern, enum, and multipleOf that may be appropriate to include. Of particular note is the enum field, which provides the capability to list possible values that a user may select from (rather than supplying a value themselves). Power Automate and Azure Logic Apps render these as a dropdown selection in the user interface, which is useful for ensuring that the supplied data is valid. Also useful for validation purposes is the pattern field, in which the user provides a regular expression against which the supplied value will be evaluated. For more information on regular expressions, visit https://learn.microsoft.com/en-us/dotnet/standard/base-types/regular-expression-language-quick-reference.
The parameters object for a get operation to the /v1/feed endpoint within the sample Asterioids NeoWS connector could be structured as follows (note the use of enum to provide a list of pre-defined starting date values):
"get": {
…
"parameters": [
{
"name": "start_date",
"in": "query",
"required": false,
"type": "string",
"default": "2023-05-01",
"enum": [
"2023-01-01",
"2023-02-01",
"2023-03-01",
"2023-04-01",
"2023-05-01"
]
},
{
"name": "end_date",
"in": "query",
"required": false,
"type": "string"
}
]
}Parameter Schema
The schema element defines an object that will comprise the body of the request. While it can be a primitive or an array, it is most often declared as an object. To avoid the repetitive declaration of identical objects, schemas are often combined with the $ref property to make them reusable. Wherever a schema element appears, the parameter properties change somewhat, with things like summaries and descriptions moving down into the schema. The structure of certain fields also changes, with the required field becoming an array of required properties instead of a Boolean true or false value.
It can all seem a bit confusing in the documentation but in practice it is actually quite simple. As an analogy, consider a hypothetical API that returns data about cars based upon a set of filters. When making the request as a get operation, it is already assumed that the object type is known, so only the filter names and values are necessary—for example, things like year, make, model, trim level, color, number of doors, and so on. The definition only needs to list each parameter and provide some contextual properties. When executing a post operation, which contains a payload that is a structured object rather than a collection of inputs, the properties of that object must first be defined by declaring the type as object and listing each property, along with its individual metadata, within the properties element. It is akin to asking the API “give me all the blue 2020 Ford Focus GT coupes in your database” versus saying “here is an envelope containing all the information about the cars I need from your database”. The difference is subtle, but important, with the former being an implicit request and the latter an explicit request.
The following example adds a post operation to the Asteriods /v1/feed action with the base parameters as part of an object within the schema element and required set to an array that lists the fields in the subsequent properties section which must be included:
"post": {
"parameters": [
{
"name": "startDate",
"in": "body",
"schema": {
"type": "object",
"required": [
"start_date"
],
"properties": {
"start_date": {
"type": "string",
"description": "Start date of query"
},
"end_date": {
"type": "string",
"description": "End date of query"
}
}
}
}
]
}One method is not inherently better than the other, with the notable difference that an object within the body of a post, put, or patch can be significantly more complex than a simple collection of primitive values in a get request. Many API providers support both but some may be more particular about allowing certain types of operations on each endpoint. Also worth remembering is that get requests cannot transmit files (binary objects or byte streams), and a post request cannot transmit a file with in set to body. It must instead use the formData value.
The user interface that Power Automate and Azure Logic Apps provide for supplying data to actions is a simple collection of input fields. For this reason, it is best to construct flat schema objects for parameters and avoid nested field relationships. These do not present well and are confusing to the user. If the target system requires a complex object in the body of the request, consider ways in which a simple object structure can be presented to the user for data capture. Next, use the Code step to construct a more complex representation that matches the API provider requirements.
Consumes/Produces
Both the consumes and produces elements set boundaries around what type of data will be sent or accepted, respectively. These boundaries are based on MIME (Multipurpose Internet Mail Extensions) or media types, which is a set of standardized identifiers for various kinds of files sent over the internet. They are expressed in the format type/subtype, sometimes including an optional parameter used to provide additional metadata or specificity (for example, text/plain;charset=UTF-8). The type and subtype are both case-insensitive but the parameter may be case-sensitive.
There are two classes of media type: discrete and multipart. A discrete media type represents a single file or medium, whereas a multipart type indicates an object comprised of multiple component types. Alternatively, the multipart designator can be used to encapsulate multiple files sent together as part of a single transaction. For more information on MIME types and how they are used in internet communications, refer to https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types.
When used within the consumes or produces element of a connector definition, an array of MIME types restricts either the input or output data supported by the operation. For example, an operation with both elements set to a value of application/json will only permit JSON-formatted data to be sent and received. It is not uncommon for the two elements to differ in their contents, such that an application/json request returns an image/png response. If it is not important to strictly limit the input or output types, these elements may be left empty (represented by opening and closing square brackets with nothing in between).
The following example demonstrates an operation in which the request MIME type is limited to a JSON object and the response to an audio file in either MP3 or WAV format:
"consumes": [
"application/json"
],
"produces": [
"audio/mp3",
"audio/wav"
]Responses
Responses are similar to parameters in that the output can be expressed as an object defined within a schema element; however, there are some notable differences. To begin with, there are fewer property fields for a response, typically limited to a list of included headers, a description, any helpful examples, and the associated schema. If the schema is omitted, then it is assumed that no content is returned as part of the response.
Responses must include either a default property, one or more HTTP status codes, or both. If status codes are specified, then the default property (if one exists) will be used for all responses that do not match the provided status codes. Since there are too many possible status codes to list in a connector definition, it is common to include at least one success code (such as 200), one or more of the most common error codes (404, 500, etc.), and a default element to catch everything else. Take note of the fact that even though HTTP status codes look like integer or decimal values, they are specified within a definition as strings. Defining a response in the connector creation wizard uses the same example-based approach as requests.
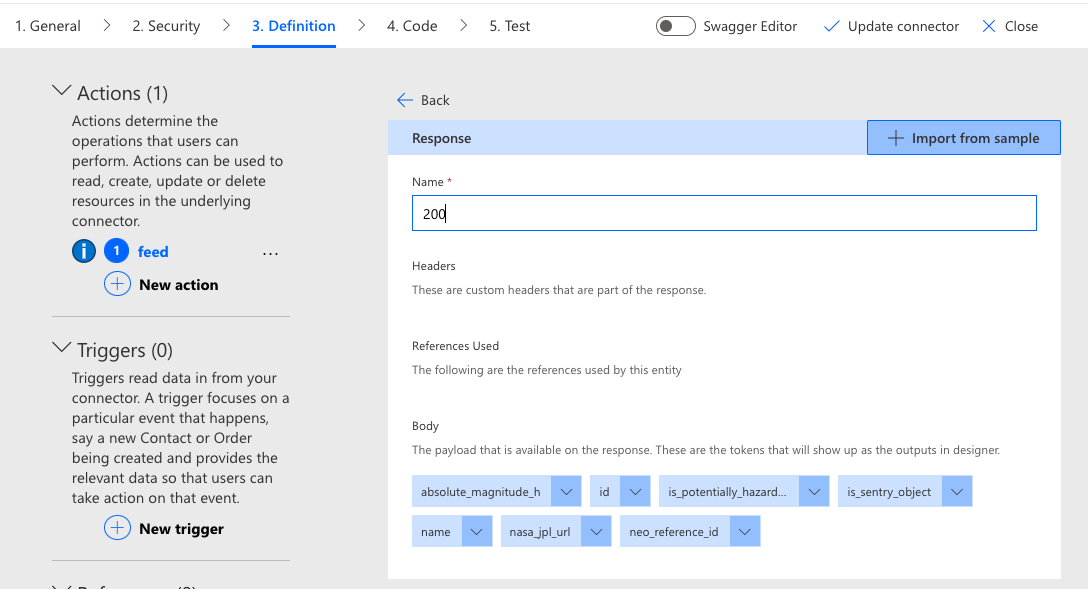
The exact codes that are available and the structure of the response are entirely dependent upon how the API provider has implemented their service. It is common for all error responses to share the same status code in the response, even though the underlying error may be quite specific. A response of 400 is the generally accepted code for “something has gone wrong." However, there are numerous sub-codes that provide more detailed information. Examples include the commonly encountered 404, indicating that the requested resource cannot be found, and even highly specific variations on a code, including things like 400.6 (invalid request body) and 404.6 (verb denied). For this reason, most providers limit their responses to only a few high-level codes.
The following code snippet describes two possible responses—a success that returns a file and an error that returns a JSON object containing the error details:
"responses": {
"200": {
"description": "OK",
"schema": {
"type": "file"
}
},
"400": {
"description": "ERROR",
"schema": {
"type": "object",
"properties": {
"error": {
"type": "string",
"description": "Result",
"x-ms-summary": "Result"
}
},
"example": {
"error": "string"
}
}
}
}Responses often contain complex, nested JSON objects. Power Platform has no difficulties handling these but accessing them in the flow designer or an expression can be tricky. This is because the user must navigate the object hierarchy to obtain the output value they desire. The user interface does not make it easy to visualize this hierarchy and clicking through dynamic output values that keep changing as it drills down through the structure is not very effective. If possible, response objects should be flattened to streamline the output and provide a better user experience; however, this can only effectively be done with code which, like the aforementioned request object flattening, is a pro developer task. If the response structure is out of the creator’s control, it may be necessary to engage a developer to assist with this part of the process.
Examples
It can sometimes be unclear to readers of a definition how exactly requests should be constructed and how responses should be handled. Providing examples of inputs and outputs can simplify the process and make the definition easier to implement. This especially true for more complex definitions with extensive schemas and references. It also makes testing much faster and easier, as example objects are available for humans to make immediate use of without referring to the underlying documentation. Automated testing tools also rely upon examples to construct known good (and bad) request routines.
A good example provides just enough information to execute a successful request or interpret a response. If there are multiple ways to configure an input such that a single example is insufficient, consider providing a link using the externalDocs property for users to get more detailed information. The following snippet demonstrates how to construct a request object for the post operation in the sample Asteroids NeoWS connector:
"example": {
"start_date": "2023-01-01",
"end_date": "2023-02-01"
}Conclusion
There are numerous ways to configure the security settings and actions in a connector definition. Each has properties and elements that dictate how the connector will be secured, presented, and configured within apps and workflows. From simple, unauthenticated requests to retrieve data to posting complex objects or sending files over a connection secured by an OAuth token exchange, each connector can define multiple combinations of activities and related authorization mechanisms. Learning how to interpret an API specification, what information is contained within the various sections, and how that information is translated into the operations within a definition, are the basic building blocks for constructing usable connectors.
In part four of this series, we will demonstrate how to make large definitions easier to manage through the use of references, and will also explore advanced connector capabilities, such as triggers and policies, in greater depth.

Eric Shupps
Eric Shupps is the founder and CTO of Apptigent, a leading provider of cloud-based software solutions for Microsoft, Salesforce, and more. Eric has worked in the industry for more than 30 years, primarily focused on Microsoft software and services, as a consultant, administrator, architect, developer and trainer. He co-hosts the Community CloudCast, has authored numerous technology articles, and speaks at user group meetings and conferences around the world.