Power Platform Connectors Performance, Hosting, and Scalability

Up to this point, the discussion has focused entirely on the inner workings of connectors themselves, without giving much attention to the application programming interfaces (APIs) that are the target of every connector action. Some creators may never need to concern themselves with how the remote systems their connectors interact with operate beyond defining functional input and output objects. There are, however, many users who build connectors to provide easier access within Power Platform to the APIs they own, host, and manage. For those creators, there are additional topics that they must educate themselves on before beginning their custom connector journey. This article is intended to demystify some of those aspects and address common concerns such as performance, hosting, and scalability.
For reference, the series outline is as follows:
- Introduction and Overview
- Connector Fundamentals
- Basic Building Blocks: Security, Actions, Requests, and Responses
- Advanced Capabilities: Triggers, References, and Policies
- Finishing Touches: Customization and Extensibility
- Power Platform Connectors Versioning and Change Management
- The Big Picture: Performance, Hosting, and Scalability (this article)
- Making It Official: Publishing, Certification, and Deployment
- Going All In: Commercialization and Monetization
- Lessons Learned: Tips, Tricks, and Advanced Techniques
Performance
In an ideal set of circumstances, connector actions should execute quickly and return processing to the parent app or flow with minimal delay. Of course, ideal circumstances rarely occur in production workloads, and numerous factors can impact the overall performance of a connector and the remote API endpoints it targets. In fact, there are many components at work that may influence how well (or how poorly) each action performs.
The following conceptual diagram illustrates many of the common steps that are involved in the execution of a single connector action.
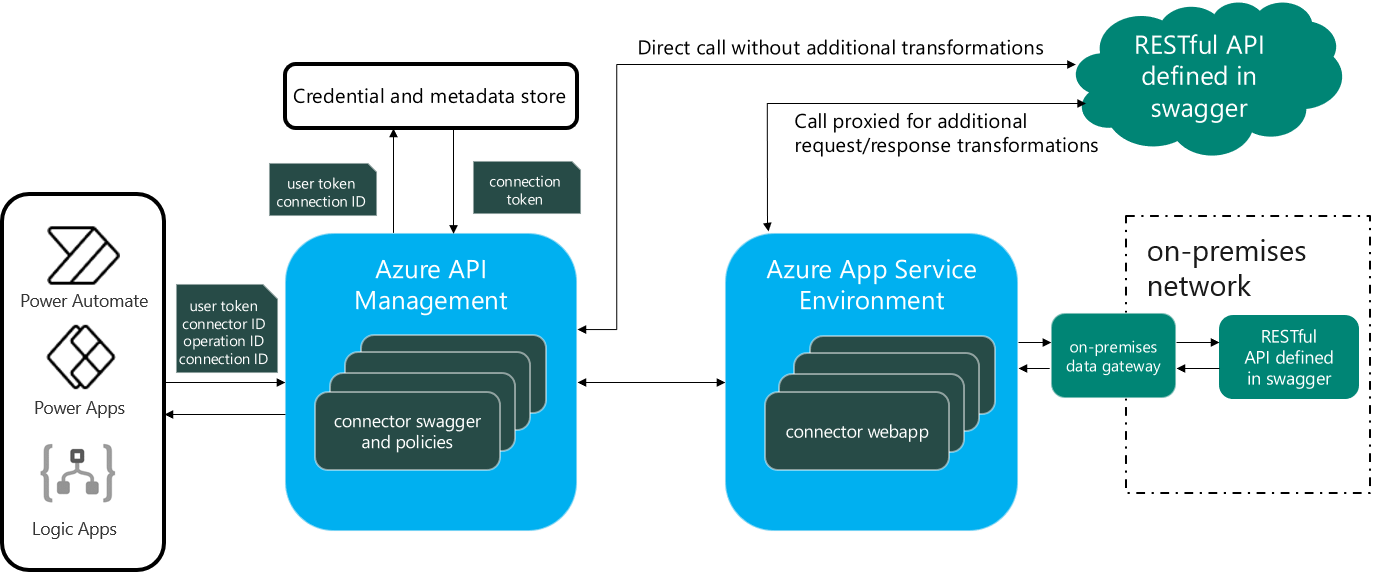
Some of the preceding steps may be under the control of the connector creator, such as code and policies, whereas others, like network routing and backend compute, may be completely out of their hands. When assessing overall connector performance, it is important to maintain focus on those elements that can be directly controlled or influenced. This gives creators practical steps to improve performance to the greatest degree possible before requesting support or assistance from intermediaries, API providers, or platform operators.
To begin with, a set of performance objectives must be established, including what to measure, how, and why. Next, it becomes necessary to understand any explicit, platform-level limitations imposed upon the connector operations, along with what design choices have been made that may result in implicit (even if unintended) limitations. Finally, performance should be extensively measured and compared against stated objectives to determine where performance issues may be occurring. Armed with this information, it is then possible to identify root causes and begin rectifying any issues.
Objectives
Performance objectives vary widely and are highly dependent upon the type, nature, and composition of each connector. They may even differ between actions in a single connector. A simple math operation that takes a small number of inputs, performs processing that requires very little computer power, and returns a simple numeric response, would be expected to perform very quickly. On the other hand, uploading a large text file for speech processing, or an image for content moderation, may consume a great deal of bandwidth and compute resources and, therefore, perform much more slowly.
It is important to set realistic expectations before measuring and optimizing performance. To establish why an action is performing poorly, it is first necessary to identify what “normal” performance parameters are. This is best done outside of Power Platform, by using testing tools like Postman (Figure 2), SmartBear, or Fiddler to submit requests to the remote API endpoints in controlled circumstances. Remember, a connector is just an OpenAPI specification, and there are many tools available that can consume the underlying Swagger file for testing and analysis.
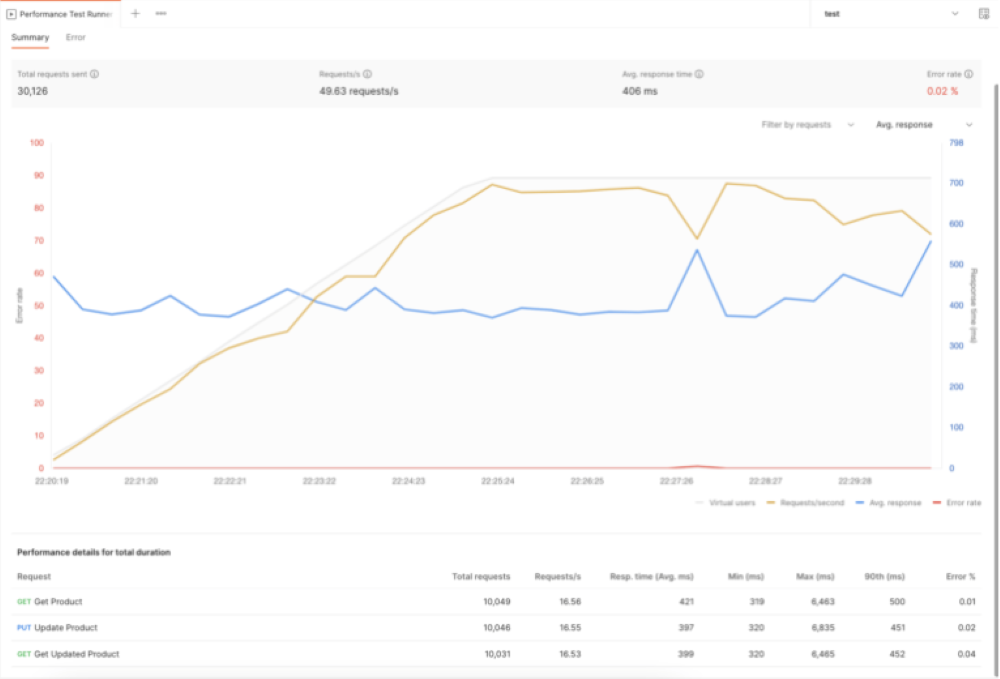
Once an action or set of actions has been measured independently, the creator has a baseline set of metrics to work from. It is unreasonable to assume that Power Platform will replicate such benchmarks in an app or flow as there is a great deal of additional processing that takes place. However, any significant variances should be viewed with suspicion and investigated. The built-in testing tools (in the Test step of the connector creation wizard) can be used to compare against off-platform metrics and should produce roughly similar numbers. (Bear in mind that code and policies may both be executed during such tests.) Additional data points can be gathered by executing connector actions in multiple environments, preferably in different geographic regions.
These off-platform and on-platform metrics form a dataset that can be used to identify normal operational parameters. In other words, they are the expected performance numbers that can be used for comparative purposes when troubleshooting poorly performing actions in real-world apps and flows. If the action performs at or near these numbers, it is within baseline, and other contributing factors should be considered to determine a root cause.
Limitations
Power Platform imposes its own set of limitations on various aspects of connector performance. Microsoft must maintain operational stability across its various service layers and even provides financially backed service level agreements for many of its cloud offerings. To do so, they, like every other cloud provider, must impose limits on various functional elements to prevent service degradation. These vary based on product, license level, enterprise agreement, support contract, and other factors, but generally most tenants are subjected to a common set of restrictions that may impact how an individual connector performs.
The following table summarizes some of the more common limitations related to connectors.
| Description | Metric | Limit | |
| Paid licensed users for Power Platform (excludes Power Apps per app, Power Automate per flow, and Power Virtual Agents) and Dynamics 365 (excluding Dynamics 365 Team Member) | Requests per paid license per 24 hours | 40,000 | |
| Power Apps pay-as-you-go plan, paid licensed users for Power Apps per app, Microsoft 365 apps with Power Platform access, and Dynamics 365 Team Member | Requests per paid license per 24 hours | 6,000 | |
| Power Automate per flow Plan 3, Power Virtual Agents base offer, and Power Virtual Agents add-on pack | Requests per paid license per 24 hours | 200 | |
| Number of custom connectors that you can create | Free plan | 1 | |
| Dynamics 365 and Office 365 plans | 1 | ||
| Per user plan | 50 | ||
| Number of requests per minute for each connection created by a custom connector | Total requests | 500 | |
| Maximum request content-length that can be sent to a gateway | Bytes | 3,182,218 | |
| Number of custom connectors that you can create | Total count | 1,000 | |
| Maximum schema count per body allowed in a Swagger file | Total count | 512 | |
| Maximum number of operations allowed in a Swagger file | Total count | 256 | |
| Maximum number of schemas per operation allowed in a Swagger file | Total count | 16,384 | |
| Maximum number of schemas allowed in a Swagger file | Calculation | Max operations * max schemas | |
| Outbound synchronous request | Seconds | 120 | |
| Outbound asynchronous request | Configurable | Up to 30 days | |
| Inbound request | Seconds | 120 |
Limitations references:
https://learn.microsoft.com/en-us/connectors/custom-connectors/faq
https://learn.microsoft.com/en-us/power-platform/admin/api-request-limits-allocations
https://learn.microsoft.com/en-us/power-automate/limits-and-config
There may also be additional limitations that factor into the performance equation for a connector. The remote API endpoint infrastructure, intermediary network transit, and platform compute power all affect the time it takes to invoke an action and receive a response. Connector design also plays a role – connectors with large code scripts, multiple policies, dynamic schemas, and on-premises gateways all require additional processing time.
It is not uncommon to discover in testing that performance bottlenecks are the result of applying lengthy script operations to requests and responses or transforming large data objects in a policy. Creators should be wary of trying to perform too many activities within a connector that could be more efficiently executed by the backend API infrastructure (such as flattening complex objects, merging datasets, or modifying response structures). Since so much of the processing pipeline for external requests is managed within protected subsystems, it is impossible to thoroughly analyze request/response performance bottlenecks to identify opportunities for optimization. A more efficient and effective approach would be to design custom connectors in such a way that the pre- and post-processing activities in code and policies do not add unnecessary processing overhead.
Measurement
It can be very difficult to precisely identify the amount of time required to execute an individual connector action within an app or flow. As mentioned previously, Power Platform performs much of its processing “behind the scenes”, and there is very little instrumentation to inform creators as to what is happening and when. That being the case, there are some techniques that creators can use to gather their own performance metrics, such as:
- Review the run history for poorly performing actions. The Show raw output link in each action includes a Date timestamp in the Headers section logging the time the request was sent. Comparing that to the next action Date entry in the flow provides a rough estimate of how long the action took to execute and process the response.
- Specify actions within the connector that perform simple GET operations to a remote resource that has some sort of tracing function, and insert them before and after slowly performing actions. Similar to a network PING, these can set measurement waypoints within a process. For example, this could be a serverless function that writes a timestamp to a log file or database each time a request is received. By calculating how long it takes for this “ping” service to execute and placing it before and after the action being analyzed, a bit of simple math produces a measurable duration for baseline troubleshooting.
- If a script is invoked in the Code step, add methods that capture a timestamp at the beginning of the action request, start of response processing, and end of response processing, then write that information to a custom header in the response. Such a header will be visible in the run history and the timestamps can be helpful in determining which set of activities consume the most time.
- If the remote API endpoint is internal or managed by the creator, add timestamp logging on the backend to capture request and response metrics. This can be very useful when combined with instrumentation in a code step to identify network bottlenecks. The time lapse between the beginning of a request in a flow and the receipt of the same request by the target endpoint is comprised of intermediary processing and communication. Any time gaps at this stage could point to network latency, routing delays, firewall rule execution, or other transit-related problems.
Remediation
Once the root cause of poor performance has been identified, steps can be taken to address the issue. This may require refactoring code, limiting policy actions, modifying backend systems, altering firewall rules, optimizing network routes, increasing processing power, or even breaking apart one action into multiple actions with smaller payloads. The solution depends entirely on the cause (or causes) and may require many small changes to produce the desired result.
Remediation steps also depend on where in the process the slowness is occurring. If an underlying component or process within Power Platform is to blame, fixing it may involve a lengthy engagement with customer support that may result in acknowledgement of the issue without a commitment to address it. Likewise, if an API provider is at fault, they may or may not choose to prioritize and correct the issue. These outcomes can be frustrating, but they are entirely within the realm of possibility and should be anticipated.
It is vitally important to always keep in mind that there may be nothing that can be done to speed up a slowly performing action. This is not to say that all avenues should not be explored in search of corrective actions, but rather that acceptance of certain outcomes is part of relying upon the often loosely connected chain of services that comprise the connector framework. In short, much valuable time and effort is often wasted in an effort to optimize the unoptimizable.
A good example of such a situation are AI-based services that perform compute-intensive tasks like converting text to speech or generating images. The sheer amount of processing power required to perform these tasks is massive and often requires more time than the platform limitations allow for a synchronous request and response sequence to complete. That is why so many generative AI responses are asynchronous in nature. Rather than trying to force such services to fit within constraints that they are not designed for, a better approach might be to limit request size, frequency, or complexity in such a way as to reasonably assure a timely response for most use cases. This approach does not solve the underlying problem, but it does acknowledge unalterable limitations and imposes boundaries that facilitate a subset of the desired functionality. In many cases, something may be better than nothing at all.
Hosting
The infrastructure needed to deliver an API that is robust, reliable, and performant can be as simple as a firewall with a few servers behind it or as complicated as a globally redundant set of physical and virtual resources spanning multiple data centers. The overall complexity depends greatly on the amount of traffic the API handles, how critical that traffic is, and whether it is relatively stable or susceptible to sharp spikes. Contributing factors also include the nature of the requests, what compute resources are necessary for the processing of each action, the amount of time required to process it, and how many dependent elements are involved. In short, it is a complicated challenge with many variables and no uniform approach that will satisfy every use case.
Bearing the above in mind, there are some common elements that each scenario must include, such as traffic management, user authorization, version management, and security. The way each element is employed varies from platform to platform, but without these basic building blocks it would be nearly impossible to effectively deploy and manage APIs for anything other than simple development scenarios. It is worth taking time to explore each of these generic components in more detail, especially for connector creators who have never built or deployed a production-ready API service at scale.
The following high-level diagram illustrates some of the components involved in deploying a basic API hosting infrastructure.
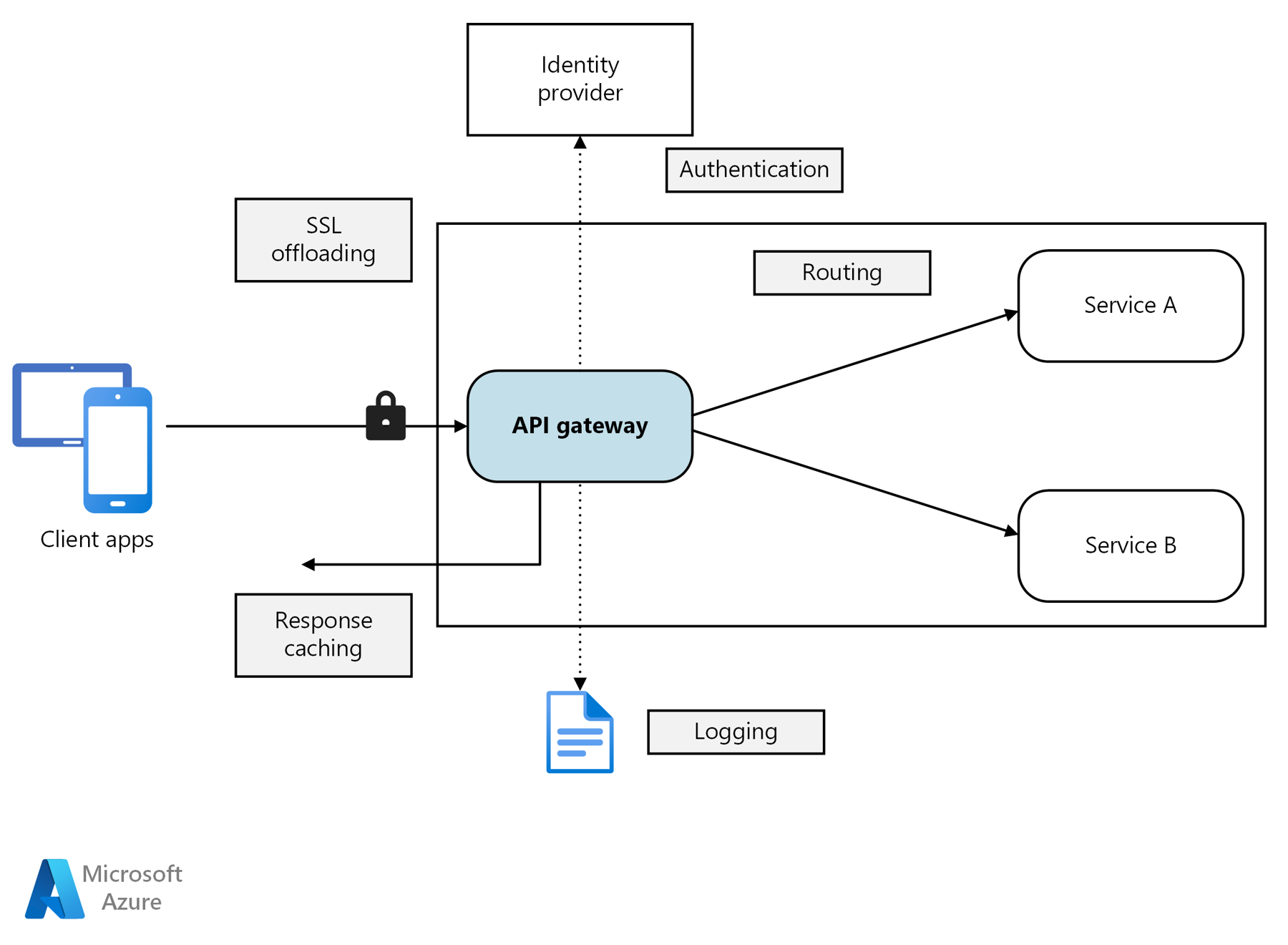
Gateways
An API gateway is an intermediary device or service that brokers requests, passes them on to the backend system for processing, and returns the response to the requestor. Backend systems can be comprised of multiple components, including web servers, databases, application firewalls, load balancers, and more. An API gateway is an important infrastructure component that allows providers to manage incoming traffic before it reaches these components. Gateways also perform additional functions, including:
- Validating authorization credentials, such as API keys and OAuth tokens.
- Providing interfaces for self-service client credential management.
- Modifying requests and responses to add/remove headers, inject payloads, transform data, and perform other tasks before the data is passed on to the back end or returned to the caller.
- Shaping traffic so that incoming requests are sent to the proper internal endpoints.
- Providing schema definition documents, responding to Cross-Origin Resource Sharing (CORS) pre-flight validation checks, and other administrative functions.
- Apply policies that execute actions, initiate workflow automation, scan requests for specific patterns, and run custom code.
The amount of functionality required in an API gateway device or service is entirely dependent upon the nature, complexity, criticality, and usage profile of the APIs themselves. A simple set of endpoints used by a small number of private users may not need much from an API gateway, whereas a public API accessed by thousands or remote systems to retrieve critical data may require a gateway with considerable capabilities, flexibility, scalability, and support.
Many vendors provide physical, virtual, and software-as-a-service (SaaS) API gateway solutions. Microsoft offers a competitive solution in the Azure API Management service. It has a wide array of features to suit most workloads, along with a scalable architecture, built-in self-service client portal, and pay-as-you-grow or dedicated pricing. Regardless of which device or service is ultimately selected, there is a very good chance that as your API size, complexity, and utilization grow, an API gateway will become a critical part of the overall architecture.
Credentials
Securing API endpoints is a crucial part of the hosting and delivery process but managing client credentials can be very time consuming without an automated, self-service mechanism. In the simplest authorization scenario, the user need only supply a predefined key when making a request. It does not really matter how such keys are constructed, assuming at least some basic form of random generation and encryption is employed, but rather how many users need them and how often they are changed. Ideally, users should have the ability to create, modify, and delete keys themselves, which requires some sort of system to store, validate, disable, and remove keys as needed. (Most API gateways provide such capabilities.)
If the APIs are to be secured with a token-based mechanism like OAuth, the configuration and management tasks for both the provider and consumer become much more complex. Unless usage is limited to only a small number of clients, OAuth configuration should be self-service and fully automated whenever possible. Most API gateways provide OAuth integration along with key management. Depending upon the cloud stack and authentication mechanisms at play, however, setting it all up properly can be a highly technical process requiring integration with multiple backend systems and components.
It is best to avoid configurations in which the only credential options are none or basic. The former introduces too many opportunities for abuse, while the latter relies upon the transmission of usernames and passwords in clear text that is easily readable by bad actors. Similarly, to provide a basic level of secure data exchange, API systems should use Secure Sockets Layer (SSL) and the HTTPS protocol for all publicly accessible endpoints, rather than the more insecure HTTP protocol. Although Power Platform supports HTTP endpoints, their use should be avoided in any production connectors. (Carefully scrutinize any API provider that does not offer HTTP endpoints as it demonstrates that security is not their primary concern.)
Subscriptions
Many API credentials are tied to a subscription of some sort that defines utilization boundaries and limits. Even an unlimited use subscription is likely to impose limits on the number of requests that can be made within a specific time period or put a cap on the number of concurrent operations. Subscriptions are often associated with monetization or billing contracts, many of which offer tiers of service at different price levels.
API management platforms typically include the ability to configure and manage user subscriptions but not all of them support monetization features. Azure API Management, for example, has no monetization capabilities, requiring customers to deploy their own solution for paid subscriptions. Many such platforms offer some type of bundled service that includes components like a gateway, billing, and credential management, and there are also standalone solutions for each element (both paid and open source).
The following screen capture demonstrates how subscriptions are created and managed in Azure API Management.
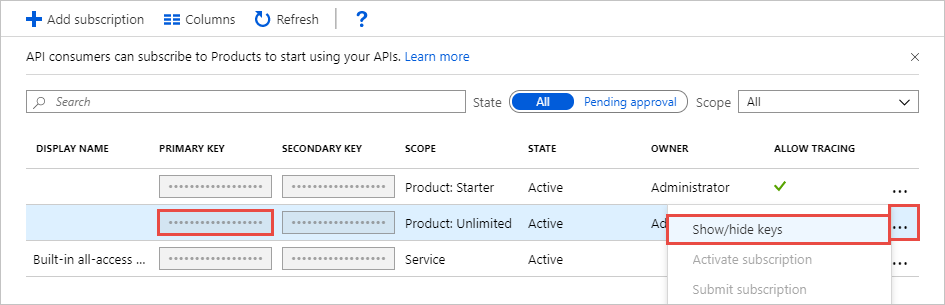
Regardless of whether the APIs that service a connector are revenue-generating, subscription management still plays an important part in the solution architecture. Without limits and boundaries, performance becomes difficult to manage and service levels impossible to predict. Even a basic set of APIs should align users with subscriptions, if for no other reason than to track who is accessing what, when, and how often.
Releases
As discussed in a pervious article, most APIs go through some sort of evolutionary process, often beginning with a small number of endpoints and expanding these capabilities over time. Change management can be a challenging process, both for APIs and the connectors that rely upon them. Avoiding service interruptions when changes are made is of utmost importance.
One way to achieve this is by using versions or releases. (These terms are interchangeable when discussing the API lifecycle.) When new functionality becomes available, or existing functionality is modified, a new release can be created that supersedes the previous version. On many platforms, a new release can be created, then tested and validated, before being published for public consumption. This is an ideal method for ensuring little or no user interruption will occur before making a new release available. Ideally, new releases will have no impact on existing action requests, with users only needing to modify their connectors to take advantage of newly available versioned endpoints (such as the /v1 and /v2 path syntax discussed in Part 06 – Power Platform Connectors Versioning and Change Management).
Sometimes, it becomes necessary to deprecate or remove API functionality. As this would result in breaking changes to existing connectors, release management ensures that new subscriptions only have access to the latest version of an API, while existing users maintain their association with older versions for some period of time or until some action is taken (like renewing a subscription or refreshing an API key).
Products
A common use case for API providers is to group individual APIs into combined or bundled offerings. API management platforms often refer to such combinations as Products. A single product can contain one or more APIs or API sets and target different user profiles. For example, a government agency may publish multiple severe weather APIs, including one for snowstorms, one for hurricanes, and another for tornadoes, each with a different base URL path (such as “snow.weather.gov” and “hurricanes. weather.gov”). As this would require three individual connectors (as each can have only one base path) and possibly three individual subscriptions, it may be more efficient to combine them into a single base path like “storms.weather.gov”, enabling access to all three APIs in a single connector.
There are several ways this can be achieved, one of which is by grouping the disparate APIs into a single virtual API product with its own base URL. In this manner, each API can continue to be managed individually, with a policy at the product level responsible for routing incoming requests to the proper location. This simplifies the connector story, with a single base URL and subscription providing access to all three APIs.
Another use case for products is rate limiting and throttling, especially with regards to paid subscriptions. Consumption plans enforced by policy can provide multiple price levels, each with a limit on the number of total requests, throughput, or concurrency. Extending the previous storms product example, the agency might offer a free consumption tier that limits users to less than 1,000 requests per month, and paid tiers ranging from 1,000 to 100,000 requests per month. Users can then select the product plan that best suits their needs.
Creating a product in Azure API Management involves configuring the product parameters, selecting the associated APIs, and defining policies.
Protection
As with any other service available over the internet, APIs must be protected against the actions of bad actors and those with malicious intent. Connector actions that constantly fail due to remote endpoints being unavailable as the result of denial-of-service attacks, certificate spoofing, script injection, credential hijacking, or a host of other preventable reasons will quickly be abandoned.
There are several solutions for protecting API endpoints, including traditional firewalls, web application firewalls, packet inspectors, traffic managers, and more. An “all of the above” methodology is obviously the most comprehensive but may not be affordable to anyone other than very large API providers. At a minimum, port-based firewalls should be employed to isolate traffic to a very small range of known IP protocol ports, along with application firewalls that contain request/response analysis rule sets that comply with the OWASP standards. These rules, which are regularly updated and expanded, provide a base level of protection against known threat vectors but constant monitoring is necessary to identify new threats.
API design also plays a role in protecting the overall system. Endpoints should accept only the defined parameters and data types, rejecting any requests that vary from the specification. They should also expose only the necessary operation types. If a GET is sufficient, then block or return an error for any POST, PUT, DELETE, or MERGE requests. Complex payloads should be validated against a strict schema definition to ensure the rogue data cannot be included in any requests. (Accepting dynamic objects in request payloads opens the backend system up to a wide range of attack types.) Generally, an API should only expose the absolute minimum functionality necessary to satisfy agreed-upon use cases and nothing more.
Scalability
As API utilization increases, the infrastructure supporting it must expand to handle the growing workload effectively. This ability to scale on demand to meet capacity requirements is an essential characteristic of quality API design because it directly impacts the user experience. APIs that can scale seamlessly allow for fluid growth in both user base and data volume, without incurring operational failures or performance degradation. An API that does not scale well will encounter numerous challenges, such as latency issues, service outages, and increased costs, which could all result in customer dissatisfaction and potential abandonment.
An API that fails to scale will encounter bottlenecks during periods of high demand, leading to slow response times, dropped requests, and response failures. These delays can disrupt user applications or services that rely on timely API responses. A non-scalable API infrastructure may require constant manual intervention to adjust resources, adding overhead and complexity. Insufficient scalability can result in spiraling costs due to the need for excessive resources to maintain even a baseline level of performance.
There are numerous aspects associated with API scalability, from the underlying code to database dependencies, network transit speed, raw compute processing power, and much more. To further complicate matters, the level of scalability available within an API depends as much upon what it does as how it does it. For example, an API that performs mathematical calculations using virtualized compute resources may be primarily constrained by the number and power of processors available on the virtual host. This is a relatively simple scalability problem that can be addressed by adding more physical compute capacity. Alternatively, an API that retrieves large amounts of data from several backend databases over a virtual network has a much more complicated scalability story that must take into account the physical resources, compute capacity, transmission speed, and concurrent load associated with multiple resources. Implementing optimizations for each of these scenarios requires a completely different approach.
For the sake of simplicity in addressing the most common API scalability concerns, this article focuses on the four major areas that apply to any technology stack or cloud platform:
- Horizontal
- Vertical
- Regional
- Global
Horizontal
Horizontal scalability refers to the capacity to handle more workload by adding instances of API infrastructure elements, such as servers, firewalls, routers, and databases. This enables the system to accommodate increases in demand without modifying existing components. New servers can be added to share the responsibility of handling incoming requests, or additional load balancers provisioned to better distribute the overall workload. For instance, if a connector is used in a workflow that has seasonal spikes in utilization, additional instances of the API gateway, load balancer, web application firewall, functions host, and database can be spun up to handle the extra load, thereby maintaining a smooth user experience. Scaling horizontally can be incredibly expensive and it depends upon having access to sufficient infrastructure resources. If there are no more virtual machines available to deploy, then expansion halts when the final resource is brought online.
Vertical
Vertical scalability takes a different approach from horizontal scalability. Rather than increasing the number of instances, vertical scalability focuses on adding more power to an existing instance. This could involve augmenting the CPU, memory, or storage resources to enhance its capabilities. While this is often quicker and sometimes simpler to implement, it comes with its own set of limitations like hardware or software constraints. For example, a financial-trading analytics service might need to increase its server capabilities temporarily to manage a heightened load during peak trading hours, reverting to normal levels afterward. This sounds easy to achieve, but if the provider does not own enough licenses to add more processing power or the host system is already at maximum capacity, then vertical growth might be restricted.
It is quite common to combine both vertical and horizontal scalability (adding a greater number of more powerful instances), especially in response to very large spikes in traffic. Depending upon how the API infrastructure is designed and operated, this process may require some amount of downtime while existing resources are expanded and new resources deployed. As any outages could be detrimental to service level agreements and customer satisfaction, a combined horizontal and vertical approach should be planned carefully to minimize any impact to the flow of requests and responses.
Regional
Regional scalability involves distributing instances of an API across different geographic locations. The key benefit of this approach is the reduction of latency, as it places API resources closer to where they are consumed. This is achieved by deploying API endpoints in data centers that are strategically located across various regions. Imagine a global streaming service that deploys its API instances in data centers around the world; this would enable faster content delivery to local audiences, enhancing user satisfaction.
Regional scale-outs can be complicated due to the number of infrastructure components involved, each with its own configuration requirements and deployment procedures. There may be limitations that prevent all elements within an API solution from being regionally isolated. For example, a regional deployment of Azure API Management results in only the gateway component being replicated to additional regions – the instance’s management plane and developer portal remain in the primary region. This may not be ideal for jurisdictions that require fully isolated data residency. Be aware of any such limitations associated with the chosen API management solution before contemplating regional scalability as a solution for ensuring optimal service delivery.
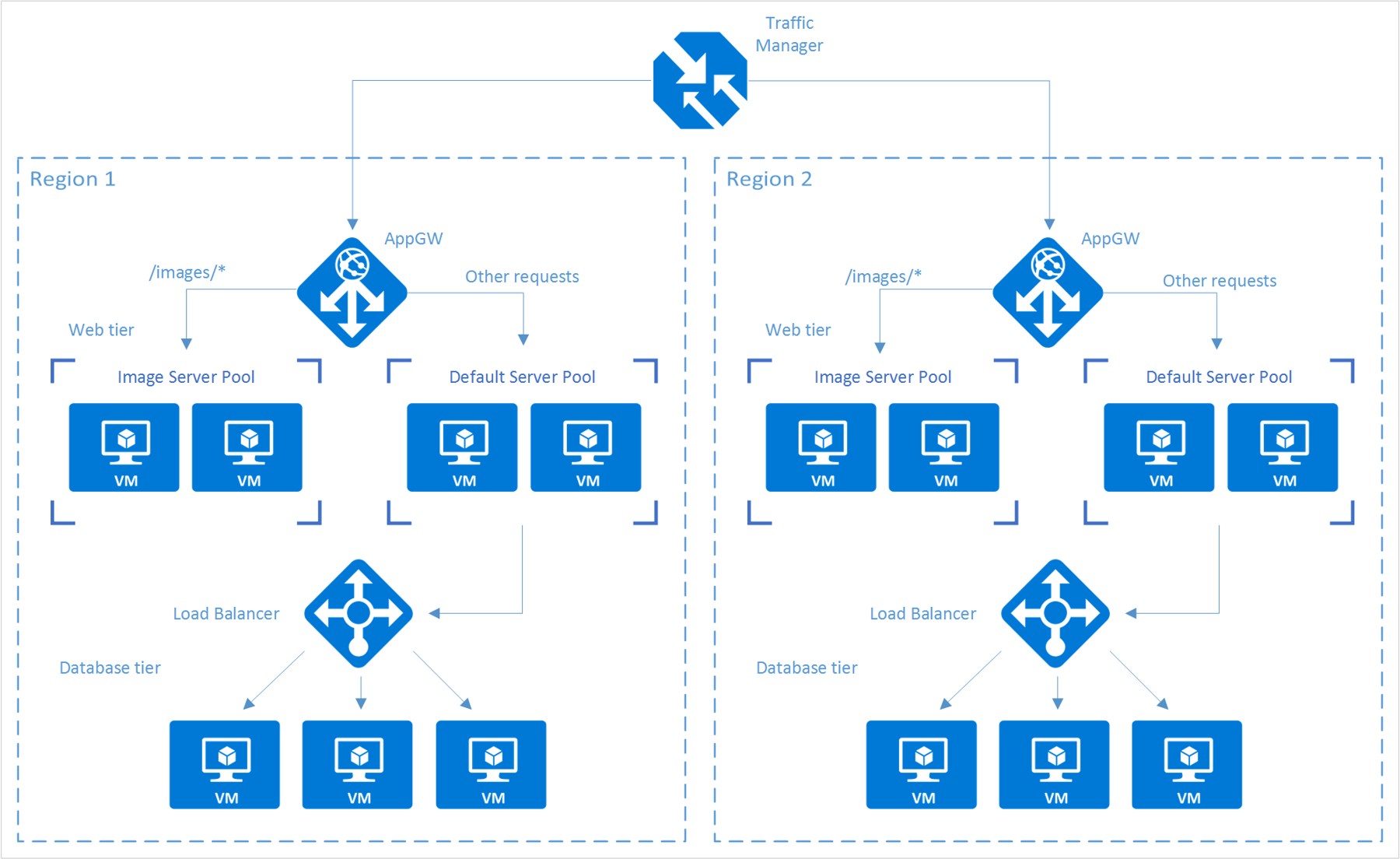
The following conceptual diagram illustrates a generic compute scenario replicated across regions using traffic managers, load balancers, and application gateways in Azure.
Global
The uppermost tier in scalability involves a comprehensive set of architectural and operational practices aimed at ensuring an API can meet demand on a global scale. Unlike other forms of scalability, global scalability often combines elements of both horizontal, vertical, and regional scalability. Additionally, it may incorporate other strategies such as the use of content delivery networks (CDNs), advanced caching mechanisms, and global load balancing. A pertinent example would be a social media platform with a worldwide user base. Such a platform would require a globally scalable API to function smoothly, regardless of where in the world requests are coming from.
Scaling a solution globally can be very expensive and requires a great deal of planning, testing, and validation. Fortunately, most cloud platforms offer some level of global redundancy and scalability for numerous platform-as-a-service (PaaS) and infrastructure-as-a-service (IaaS) components. There is no one-size-fits all approach to scaling a solution for a worldwide audience. The particular combination of elements necessary to deliver the performance and reliability that users expect may vary widely from one API to another. If there is an expectation that an API will need this level of scalability, API providers should perform careful due diligence before selecting a hosting platform to ensure that it offers all the components required to build out a comprehensive solution.
Conclusion
Custom connector performance is dependent upon multiple factors, some of which are related to the design of a connector (such as the number of policies or length of code scripts), while many are directly influenced by the APIs each action targets. Troubleshooting performance issues requires a meticulous approach that includes defining performance objectives, establishing baselines, and reductive elimination of variables through extensive measurement and analysis. Once a root cause has been established, corrective actions can be taken by the connector creator (in the case of poor design decisions) or results communicated to the API provider for remediation. Creators must also take into account the limitations imposed by Power Platform itself and ensure that they stay within the established parameters.
For those creators who host the remote APIs being accessed by their connectors, there are a number of factors to consider when designing a hosting architecture or choosing an API platform provider. These include gateways, credentials, subscriptions, releases, products, security, and protection. As API utilization grows, it is also necessary to scale the underlying infrastructure up (or down) to meet demand, using various techniques related to horizontal, vertical, regional, and global scalability.
Part eight of this series will tackle the subject of connector publication, both for certified and independent publishers. This includes a deep-dive into connector packing and validation using the paconn command-line utility, a walkthrough of distributing connector documentation via the Power Platform Connectors GitHub repository, and a tour of the ISV Studio portal. Also included will be some tips and tricks for managing deployed connectors and submitting connector updates.

Eric Shupps
Eric Shupps is the founder and CTO of Apptigent, a leading provider of cloud-based software solutions for Microsoft, Salesforce, and more. Eric has worked in the industry for more than 30 years, primarily focused on Microsoft software and services, as a consultant, administrator, architect, developer and trainer. He co-hosts the Community CloudCast, has authored numerous technology articles, and speaks at user group meetings and conferences around the world.