Choosing a Big Data Analytics Platform in Microsoft Azure

In the rapidly evolving world of big data, selecting the right analytics platform for your organization's needs can be a daunting task. Microsoft Azure offers a diverse range of big data analytics services designed to help organizations make sense of their data, drive actionable insights, and fuel informed decision-making.
In this article, I’ll guide you through the process of choosing the ideal big data analytics platform within Azure, focusing on key considerations such as data storage, processing capabilities, integration, and ease of use, while sidestepping marketing jargon to present distilled, practical analysis. Let’s get started!
What Do We Mean By “Big Data Analytics”?
Big data analytics refers to the method of examining, processing, and extracting valuable insights from massive and complex datasets, which are often characterized by the 3Vs:
- Volume: The sheer quantity of data generated and stored, often exceeding terabytes or petabytes in size, which challenges traditional storage and processing capabilities.
- Velocity: The rapid pace at which data is created, collected, and updated, requiring real-time or near-real-time processing to extract timely insights and make informed decisions.
- Variety: The diverse range of data types and formats, including structured, semi-structured, and unstructured data, originating from multiple sources, which demands versatile processing techniques.
Big data encompasses datasets that are too large or complex to be handled by traditional data-processing systems, generated at high speed from various sources such as social media, Internet of Things (IoT) devices, and sensors. By leveraging advanced analytical techniques, including machine learning (ML) and artificial intelligence (AI), big data analytics empowers businesses to make more informed decisions, predict trends, optimize processes, and uncover hidden patterns or correlations that would be otherwise unattainable through conventional methods.
Given that theoretical background, I’ll spend the rest of my time in this article surveying the options for implementing a big data architecture in Azure. These options include:
- Azure virtual machines (VMs)
- Azure HDInsight
- Azure Databricks
- Azure Synapse
Please understand that the unfiltered opinions I’m about to offer you regarding these services reflect only my opinion and not the opinion of my employer, colleagues, friends, family, etc. Let’s get to it!
Azure Virtual Machines
One advantage of deploying your big data analytics architecture into Azure VMs (called infrastructure as a service, or IaaS) is you manage the entire technology stack. A disadvantage of taking this action is…you manage the entire technology stack. Do you really want to pay for all those VMs? Back ‘em up? Patch ‘em? Troubleshoot ‘em?
My advice is to consider using Azure VMs only if your big data analytics workload has dependencies that prevent you from choosing an Azure platform as a service (PaaS) offering. I suggest you look into virtual machine scale sets (VMSS), which enable you to autoscale your compute cluster based on metrics like aggregate CPU utilization.
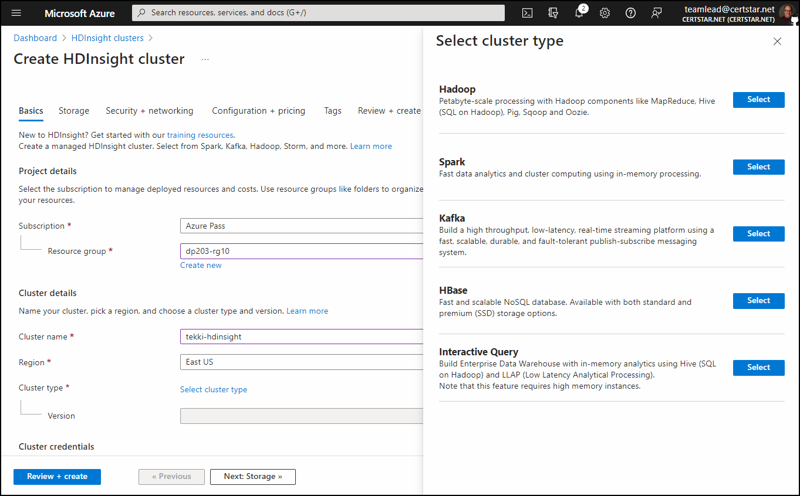
Azure HDInsight
Azure HDInsight is a fully managed, open-source analytics service provided by Microsoft Azure that enables businesses to efficiently process and analyze large volumes of data by deploying Apache Hadoop, Apache Spark, Apache Kafka, and other popular big data frameworks. HDInsight is designed to handle a variety of data types and workloads, such as batch processing, interactive querying, real-time analytics, and machine learning tasks.
With its integration into the Azure ecosystem, HDInsight simplifies the management and scaling of clusters while providing robust security, monitoring, and compliance features, allowing organizations to focus on extracting valuable insights rather than managing infrastructure. That’s the good news.
What’s the bad news? It’s really twofold:
- Azure HDInsight is on a long deprecation path. If you ask a Microsoft cloud solutions architect (CSA), they will advise you to choose another Apache Spark solution in Azure like Azure Databricks or Azure Synapse Spark Pools.
- You can’t pause or stop your clusters. This is an expensive mistake to make. Whereas Azure Databricks and Azure Synapse allow you to pause your compute clusters to save money when you don’t need them, that isn’t the case for HDInsight. As long as the cluster exists, you’re paying for it.
I would recommend Azure HDInsight only for businesses firmly committed to the Apache Hadoop ecosystem, and/or are already invested in Azure HDInsight to one degree or another. Everybody else should consider strongly standardizing on Apache Spark instead of Apache Hadoop and consider either Azure Databricks or Azure Synapse Spark Pools.
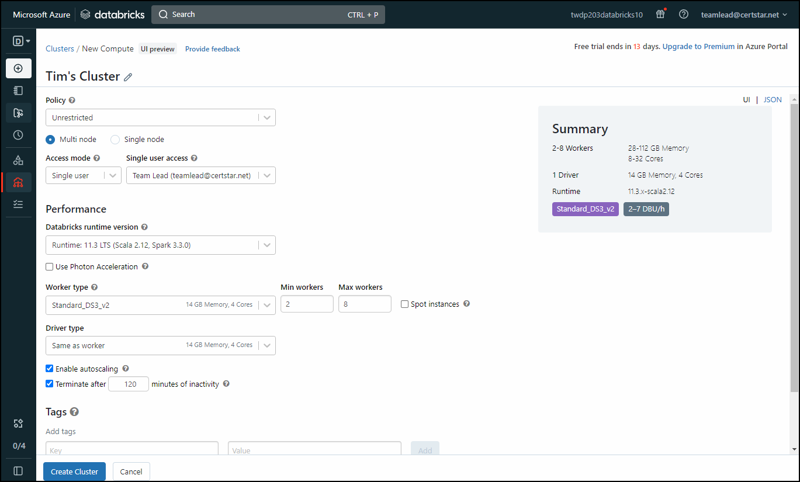
Azure Databricks
Azure Databricks is a fully managed, Apache Spark-based analytics platform that provides an optimized and seamless integration with other Azure services, making it a popular choice for organizations seeking to implement big data analytics solutions. The product isn’t totally Microsoft’s, but the outcome of a partnership between Microsoft and the Databricks Corporation.
Azure Databricks was designed to facilitate collaboration between data scientists, data engineers, and business analysts by providing a unified workspace, interactive notebooks, and streamlined workflows. “Why would a business choose Azure Databricks instead of buying a subscription to Databricks itself?” you might wonder.
Businesses often choose Azure Databricks over Databricks.com because of the former’s native integration with various data sources and other Azure services, such as Azure Blob Storage, Azure Data Lake Storage, Azure Synapse Analytics, and Azure Machine Learning. The platform's autoscaling feature and high-performance runtime environment further enhance its appeal, as they allow users to optimize resource utilization and reduce operational costs.
Despite the many advantages, there are a few "gotchas" to be aware of when using Azure Databricks. Firstly, the platform's pricing model can be complex, with various tiers and workloads that may lead to unexpectedly high costs if not managed carefully. To mitigate this, it is essential to understand the pricing structure and monitor usage patterns to optimize costs.
Secondly, organizations with strict compliance requirements may find that some features or configurations in Azure Databricks do not meet their regulatory needs. In such cases, users should carefully review the available options and engage with Azure support for further guidance. Finally, while Databricks does offer integration with other Azure services, it may not be the best choice for organizations that rely heavily on non-Microsoft technologies, as seamless integration with these tools may be more challenging or require additional customization.
Last, there’s the “elephant in the room” otherwise known as the Azure Synapse Analytics Apache Spark pool. You might reasonably wonder, “Isn’t there a tremendous amount of overlap between Azure Databricks and Synapse Spark Pools?” Yes. Yes, there is. Let’s discuss that now.
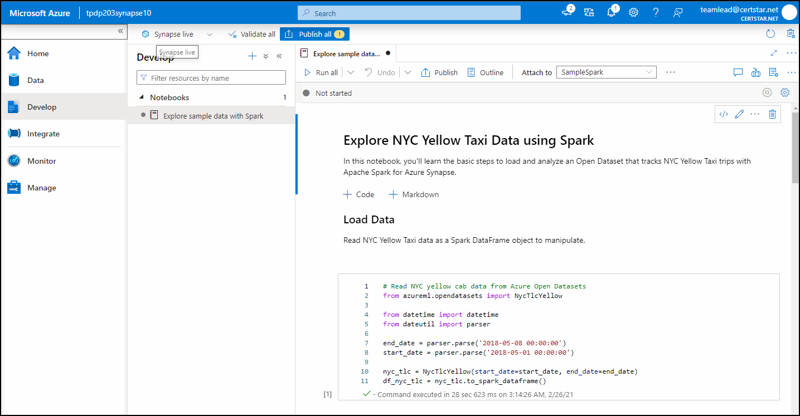
Azure Synapse
My impression is that Microsoft formed their partnership with Databricks and launched Databricks because (a) they saw HDInsight probably wouldn’t work out in the long term; and (b) they needed a solid, cloud-hosted Apache Spark platform in their cloud as soon as possible.
Azure Synapse Analytics is an integrated analytics service designed to bring NoSQL big data analytics and SQL data warehousing together, enabling users to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. It offers two types of processing pools: SQL pools (formerly known as Azure SQL Data Warehouse) and Apache Spark pools.
SQL pools provide a massively parallel processing (MPP) architecture for large-scale data warehousing tasks, allowing users to query and manage relational data using familiar SQL-based tools and languages. Apache Spark pools, on the other hand, leverage the capabilities of Apache Spark to process and analyze large volumes of structured and unstructured data in memory.
Synapse Spark pools support various programming languages such as C#, Python, Scala, and R, and are well-suited for advanced analytics tasks like machine learning, graph processing, and natural language processing.
Given this background, we should go a bit deeper in contrasting Azure Databricks and Synapse Spark pools. Consider the following comparison points:
- Integration and ecosystem: Azure Databricks is an Azure-hosted third party product. Synapse Spark is a native Azure Resource Manager (ARM) service with all the native Azure integration that origin brings.
- Workspace and collaboration: Azure Databricks uses proprietary notebooks and does not natively support .NET. Synapse Spark uses industry-standard Jupyter notebooks and fully supports .NET.
- Runtime and performance: Azure Databricks uses a very high performance Apache Spark variant called the Databricks Runtime. Databricks also supports more Spark, Python, and Scala runtime versions than does Synapse Spark. Synapse Spark uses the open source Apache Spark engine as-is.
- Pricing: Both Azure Databricks and Synapse Spark integrate with your Azure subscription payment model. Both platforms enable you to pause or terminate your compute clusters to save money when they aren’t in use.
Parting Guidance
When deciding on a big data analytics platform in Azure, it's important to consider your specific use case, requirements, and budget. Before deciding, carefully evaluate your specific requirements, performance expectations, and integration needs with other Azure services. Consider factors such as ease of use, scalability, and cost, as well as the level of support and customization required for your project. Think of the big data analytics workloads you run or plan to run. How much could you benefit from them running in a Microsoft-provided cloud environment?
It may also be helpful to test each platform with a small-scale proof of concept before committing to a particular solution. Remember Microsoft offers the Azure free account. If you belong to Visual Studio Online you get monthly, recurring Azure credit. Lastly, you can try out some Microsoft Learn training modules, many of which include free access to a live Azure sandbox environment.

Tim Warner
Tim Warner is a senior content developer with Microsoft, specializing in Azure Governance. A former Microsoft MVP, in his spare time Tim teaches thousands of people worldwide how to get certified and build meaningful careers using Microsoft products. Reach Tim at his website, TechTrainerTim.com.